GraphQL is awesome but I didn’t always see it that way. The first few times I came across GraphQL I was very skeptical of its benefits because the cost of putting together a GraphQL system seemed too high and it seemed to me that all the benefits of GraphQL could be gained by having a just creating a custom JSON DSL (a query language using JSON).
However, there is a singular feature of a GraphQL system that is the key differentiator: the GraphQL schema that is served by any GraphQL server. This fact coupled with the rise of server side tooling, is why a GraphQL system is something you should seriously look at if you’re thinking of writing a JSON based query language for your APIs.
The rise of GraphQL is also perhaps a signal of the increasing amount of “type safety” tooling in Javascript community.
TL;DR
- A JSON DSL can be as expressive (actually too expressive) as GraphQL
- A JSON DSL requires no change in client-side and server side tooling
- GraphQL: Not just a query language but forces the server to publish a schema making the query/API spec a part of the code
- GraphQL: Schema can be used by the client to create tooling that automatically validates queries or “codegen”s typesafe SDKs
- GraphQL killer-design: API contract is a part of the code
- GraphQL killer-feature: Community tooling can thrive because of that design
Is a JSON DSL actually a feasible alternative?
For example, a “read” query might look like this in GraphQL:
| # Fetch authors and their articles | |
| # and relevant fields within those objects only | |
| query { | |
| author { | |
| id | |
| name | |
| articles { | |
| id | |
| title | |
| } | |
| } | |
| } |
view rawsimple-query.graphql hosted with ❤ by GitHub
But if we were to use a custom JSON query language, we might have come up with this ourselves:
| { | |
| "query": "read", | |
| "node": "author", | |
| "columns": [ | |
| "id", | |
| "name", | |
| { | |
| "node": "articles", | |
| "columns": ["id", "title"] | |
| } | |
| ] | |
| } |
view rawsimple-query.json hosted with ❤ by GitHub
As you can see, the JSON DSL is “uglier” but it’s a lot more flexible, no additional tooling and you can create your own “query language”.
Benefits of a JSON DSL:
- No change in tooling on the client
- JSON objects can be easily manipulated, especially in a language like Javascript where JSON can easily be parsed into a Javascript object.
- No change in tooling on the server
Directives and fragments in GraphQL would not even be required in JSON because you can just manipulate a POJO (plain old javascript object ?) exactly the way you need to.
What are the problems with a JSON DSL?
However, the JSON DSL approach has a few problems that start emerging when you deploy it over a long running software project or a large team.
Problems on the client-side:
Where is the “grammar” of your JSON DSL? REST-ish endpoints propose a simple, if slightly ad-hoc, grammar with HTTP verbs and simple JSON being chucked back and forth. But in a custom JSON DSL what if the “query language” changes on the server side? How you do create a specification for the client to create queries in JSON that are valid?
With a REST-ish design, there’s no query language. The JSON that is sent back and forth adheres to a “shape” or a skeleton but not really a dynamic query language. For example, you “POST” an “object”. This allows the creation of things like a “swagger” spec. For example, a “swagger” specification of your API would look like this:
| #An array of artists are returned by a GET query to /v1/artists | |
| # artists = [ | |
| # { | |
| # "name": "...", | |
| # "genre": "...", | |
| # "albums_recorded": <int>, | |
| # "username": "..." | |
| # } | |
| # ] | |
| # | |
| swagger: '2.0' | |
| info: | |
| version: 1.0.0 | |
| title: Simple Artist API | |
| description: A simple API to understand the Swagger Specification in greater detail | |
| host: example.io | |
| basePath: /v1 | |
| paths: | |
| /artists: | |
| get: | |
| description: Returns a list of artists | |
| # ----- Added lines ---------------------------------------- | |
| responses: | |
| 200: | |
| description: Successfully returned a list of artists | |
| schema: | |
| type: array | |
| items: | |
| type: object | |
| required: | |
| - username | |
| properties: | |
| name: | |
| type: string | |
| genre: | |
| type: string | |
| albums_recorded: | |
| type: integer | |
| username: | |
| type: string | |
| 400: | |
| description: Invalid request | |
| schema: | |
| type: object | |
| properties: | |
| message: | |
| type: string |
view rawswagger.yaml hosted with ❤ by GitHub
However, what is the “swagger” equivalent for a single HTTP endpoint that takes our JSON query? A query language follows a “grammar” and not really a “shape”.
On the server-side:
Serving a JSON DSL based API requires that you:
- Need to parse the incoming JSON query and
- Analyse the parsed query to perform type-checks
- Convert it to an internal form that you can break down and process (“resolving”)
This is suddenly turning from a fun “oh-hey-i’ll-just-use-some-clever-if-else-statements-to-validate-the-JSON” into “why-is-this-a-1000-line-conditional-block” or even worse “who-will-ever-maintain-this-random-new-language-that-exists-only-in-the-mind-of-the-first-employee” situation.
So then once you start off writing it in a naive way, you’ll soon realise that it’s easier to write a mini-compiler into your API server as a query parser + “resolver” that can actually understand the JSON DSL and process it in phases as opposed to dealing with the JSON DSL in an ad-hoc way.
Welcome to GraphQL
Once you go through the effort above, you’ll realise that you’ve invented a GraphQL. But it’s “uglier” (because there seems to be some key-value cruft) and there’s no standard spec.
GraphQL approaches the problem of being able to make queries against a server by enforcing a few key ideas.
Idea #1: A standard “grammar” for querying
GraphQL defines a standard grammar for a query language to read/write data. It kind of looks like a neater JSON with just the keys and allows you to pass arbitrary parameters in the query.

Idea #2: Force the server to publish a schema
The GraphQL spec mandates that a GraphQL server should publish a schema describing the types of the data and the “parameters” (arguments per GraphQL).
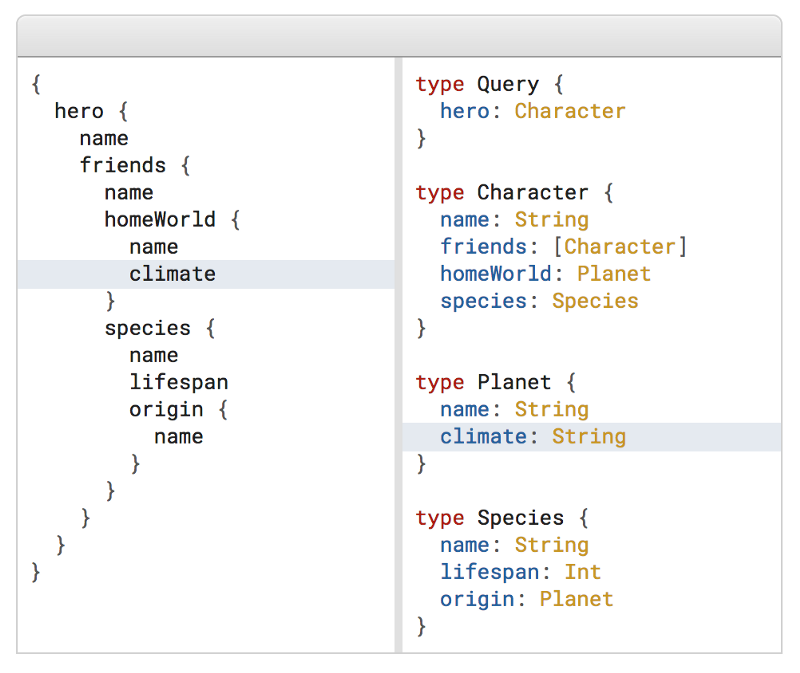 Image taken from graphql.org
Image taken from graphql.org
When the server publishes a schema, suddenly a whole host of tools and plugins become possible which can start solving the problems that were fundamental to using APIs. In fact, this suddenly makes a GraphQL server + client system better even if you didn’t have to make “queries” and could have just gotten away with simple REST.
The API specification is a part of writing the source code!
Awesome problem solved #1: API validation at build time
Whether you’re making “queries” or simple REST calls this idea of having a schema now allows you (or even better, the community ;)) to write tooling that can validate your API calls.
In fact, you can even add IDE tooling to do that validation as you write code!
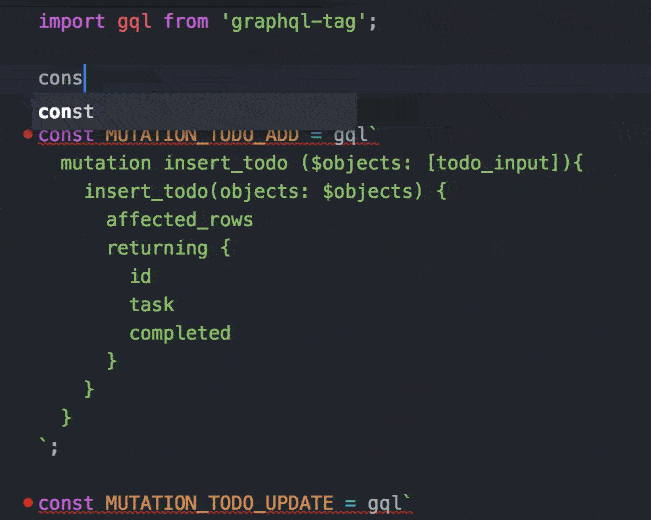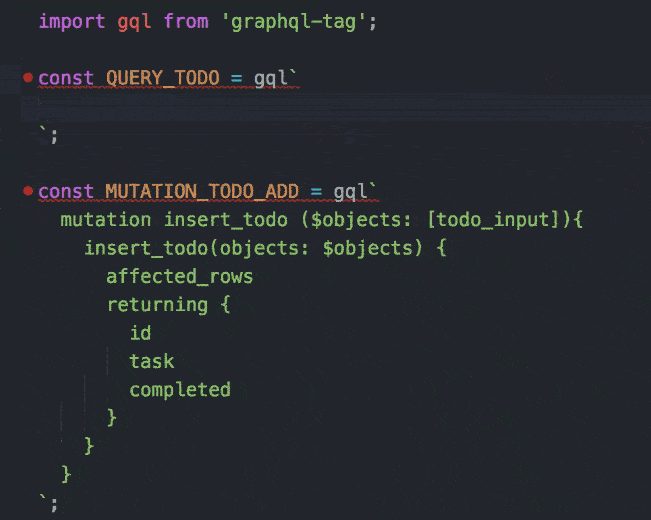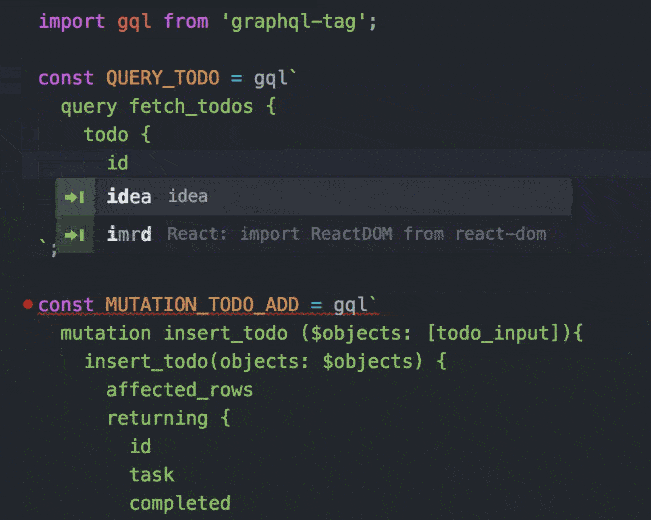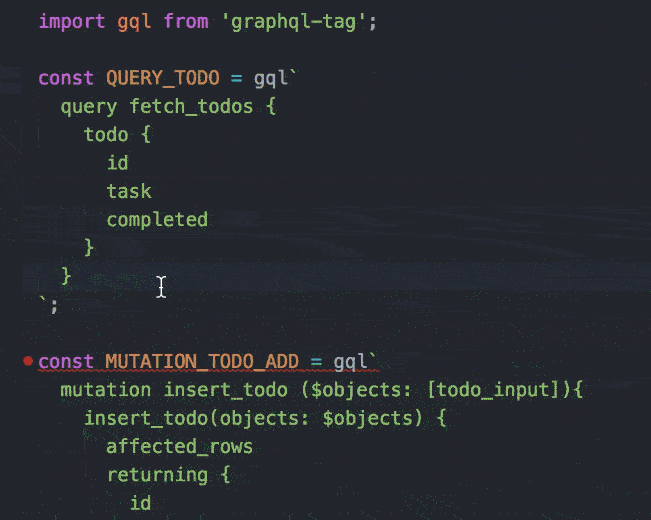 eslint configured with Atom to validate graphql queries
eslint configured with Atom to validate graphql queries
For typed language clients like Java (Android) or Swift (iOS) you can even generate the SDK code directly and nuke a large amount of boilerplate.
Awesome problem solved #2: Reduction in async client code boilerplate
Async API calls from the client can now be specified as declarative queries and the boilerplate that fetches the data and renders the UI can be neatly abstracted away. This allows you to write much cleaner UI code!
Check out a list of awesome react clients here: http://graphql.org/code/#graphql-clients
Important note: GraphQL doesn’t itself solve these problems. It’s design choices allow the community to solve these problems.
So GraphQL is awesome?
Yes, but even more so the GraphQL community is awesome! Client side tooling would have been a nightmare for whole new query language but amazing client-side tools are paving the way. Apollo’s react/react-native GraphQL client library even reduces the boilerplate required to use the results of the GraphQL query in your react component!
GraphQL servers are still a bit of a pain to write compared to writing simple REST-ish servers. A backend developer can’t think with URL paths and good old JSON and instead needs to deal with an abstract syntax tree and “resolvers” up front. Add authentication to the mix and the resolution logic becomes a little more complicated. Performance also gets harder to reason about because of the recursive nature of processing a GraphQL query. exAspArk talks about the (n+1) problem and approaches to solving it here.
But these are teething costs and not really pain-points that will remain with us forever. Better and better tooling, and more discussions around different patterns will start emerging and making life easier for the backend developer!
Summary
GraphQL is an amazing leap forward for consuming APIs! GraphQL is a million-times better than writing your own query language in JSON especially if you care about your colleagues and the longevity of your project. In fact, consuming GraphQL is far better than consuming REST because of the type-safety tooling that’s built into the GraphQL server and the client-side tooling. GraphQL servers are still a little hard to write, but it’s getting better day by day thanks to the tireless work of folks in the community!